Recent advances in data collection and computational power have enabled the development and usage of many machine learning techniques. Algorithms are being used to run self-driving cars, translate documents, and even diagnose diseases. Perhaps the most famous of these techniques is deep learning, which uses layers of neural networks to extract information from the provided input. In this post I’ll describe how neural networks work and use neural networks to classify images of insects.
What is a Neural Network?
A neural network, in its simplest form, takes a series of inputs (images, text, numbers), and passes them through a series of functions to map the input data onto the output or prediction. Let’s take a look at a basic example to gain some intuition into how they work.
The image below shows a simple neural network. The inputs are X1, X2, and X3. These inputs are combined together using numbers called weights. Weights determine how much of each input you want to pass on to the next layer. For example, if my weights were: W1: .3, W2: .5, W3: .2, that would mean I want the next layer to be 30% W1, 50% W2, and 20% W3. This summed input is then fed into another function, often a sigmoid, to produce the end prediction Y.
 Perceptron
Perceptron
This basic building block, called the perceptron, can be stacked repeatedly to form a larger network. These deeper networks can learn more complex relationships between inputs and outputs.
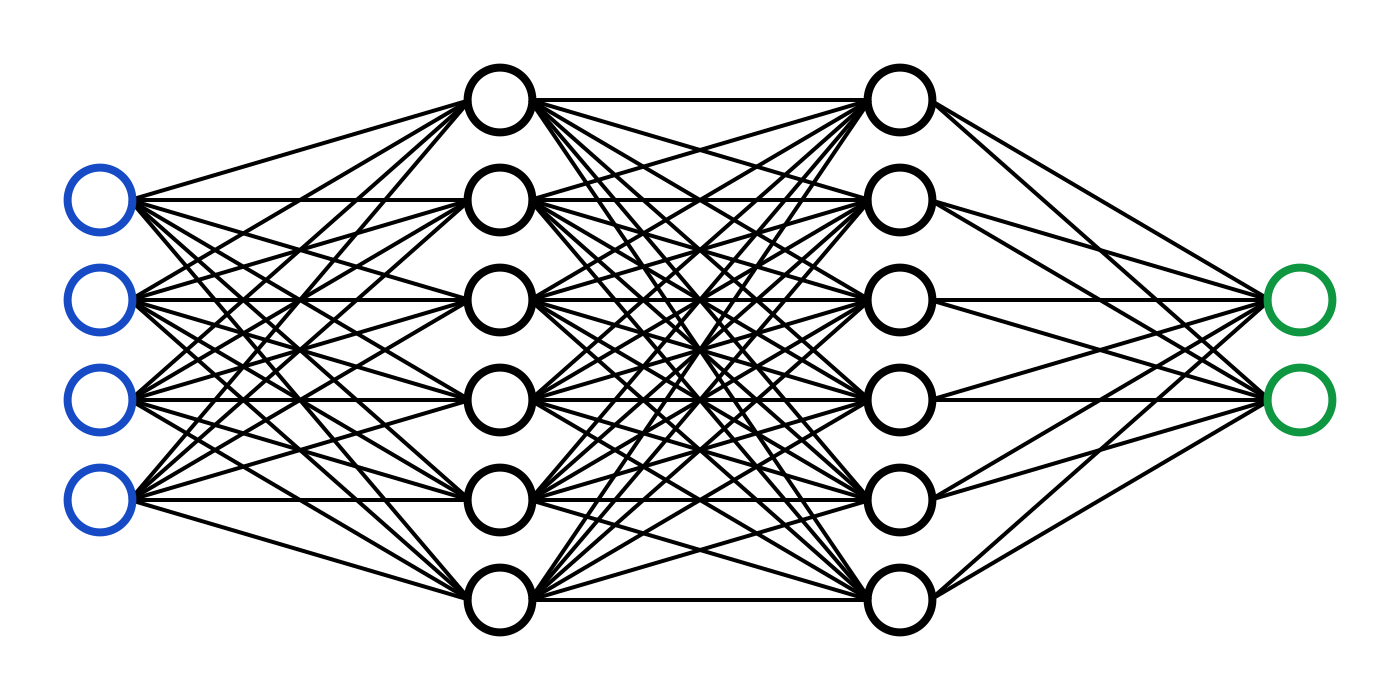 Sample Neural Network
Sample Neural Network
How do Neural Networks Learn?
The goal of a neural network is to minimize a loss function. The loss function is a function that compares the prediction of the neural network to the true value to determine how good or bad the prediction is. One such loss function, mean square error, is used to evaluate numerical predictions (ex: predicting the price of a house). This loss is the average squared difference between the predicted value and the true value.
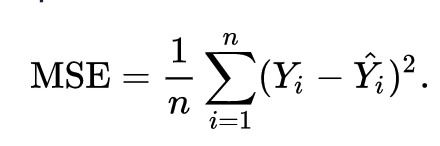 Mean Square Error Loss
Mean Square Error Loss
The computed loss value is then used to adjust the neural network’s weights in a process called gradient descent. Gradient descent takes the calculated error value and determines how to best update the neural network weights with backpropagation. Backpropagation uses calculus to find the optimal “direction” to update your weights in order to minimize the error function. The illustration below demonstrates how gradient descent works to minimize the loss.
 Gradient Descent
Gradient Descent
Networks are typically trained by feeding multiple observations into the model at once. Each set of observations is called a batch. The weights are updated every single time that you feed a batch into the network. Another term commonly used in deep learning is epoch; an epoch is one full iteration through the dataset. Deeper networks often require more epochs of training to produce good results.
We’ve established a simple framework for constructing and training neural networks. The same basic principles apply to any deep learning problem- your goal is always to minimize some loss function by adjusting the weights of a network. More complex problems can be solved using different combinations of loss functions, gradient descent algorithms, and network structures.
Convolutional Neural Networks
As I mentioned earlier, we can use images as inputs to neural networks. The most common network type applied to image inputs is called a convolutional neural network. A convolutional neural network applies an operation called a convolution to extract information, often called features, from the images. You can think of a convolution as scanning over an image and shrinking or compressing it into a smaller set of data. The gif below shows a 5x5 image being convolved to produce a 3x3 set of features.
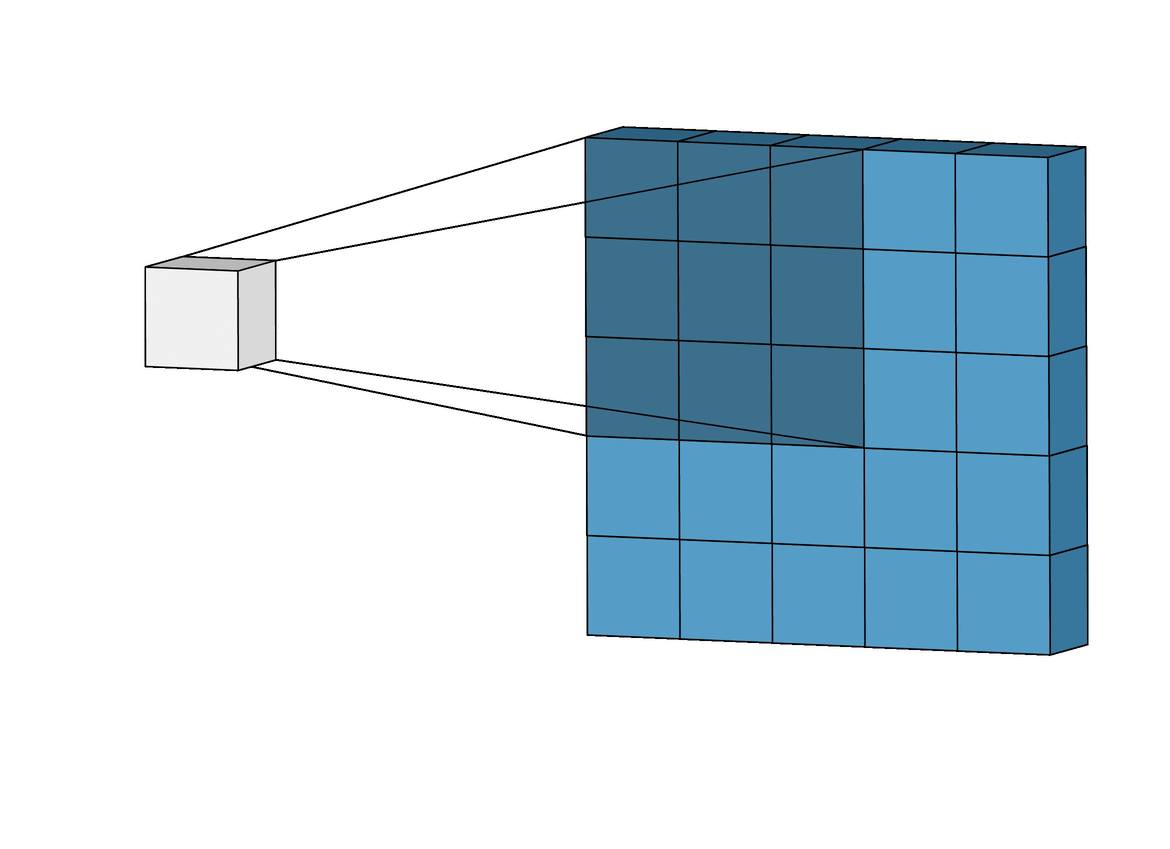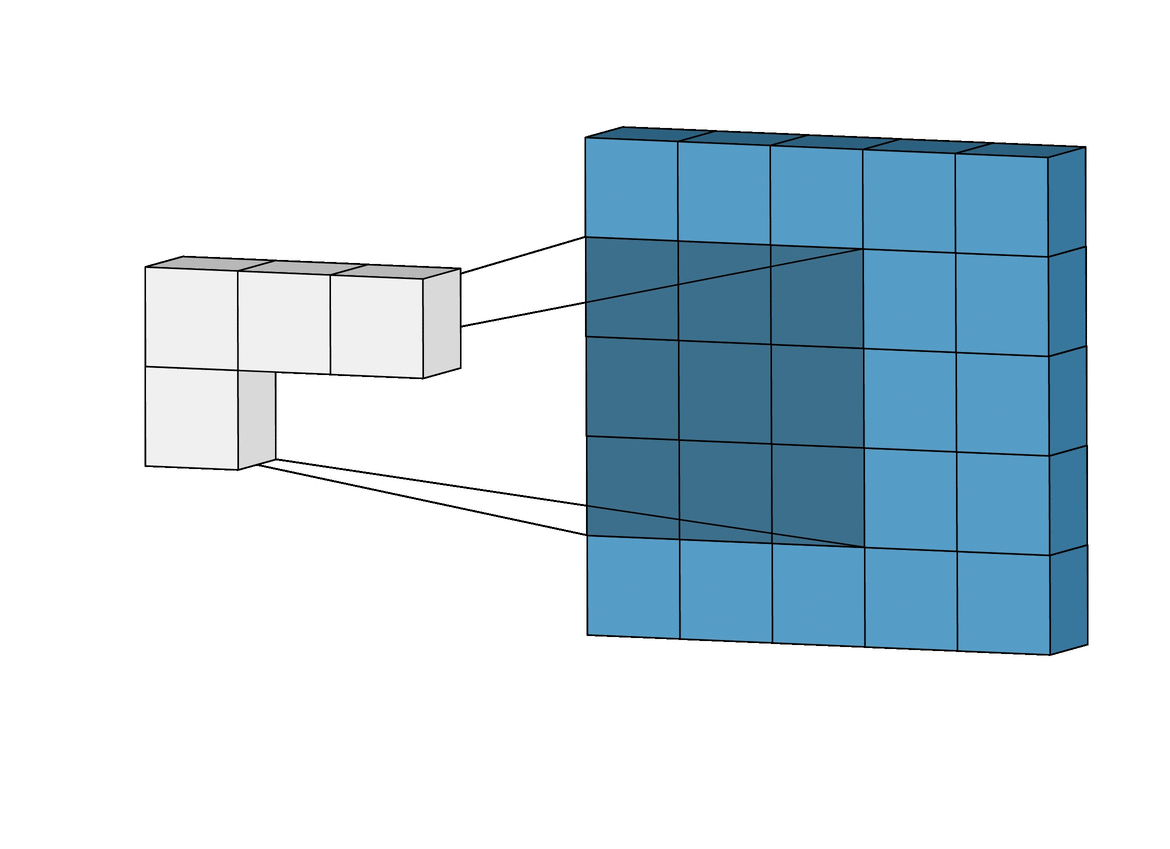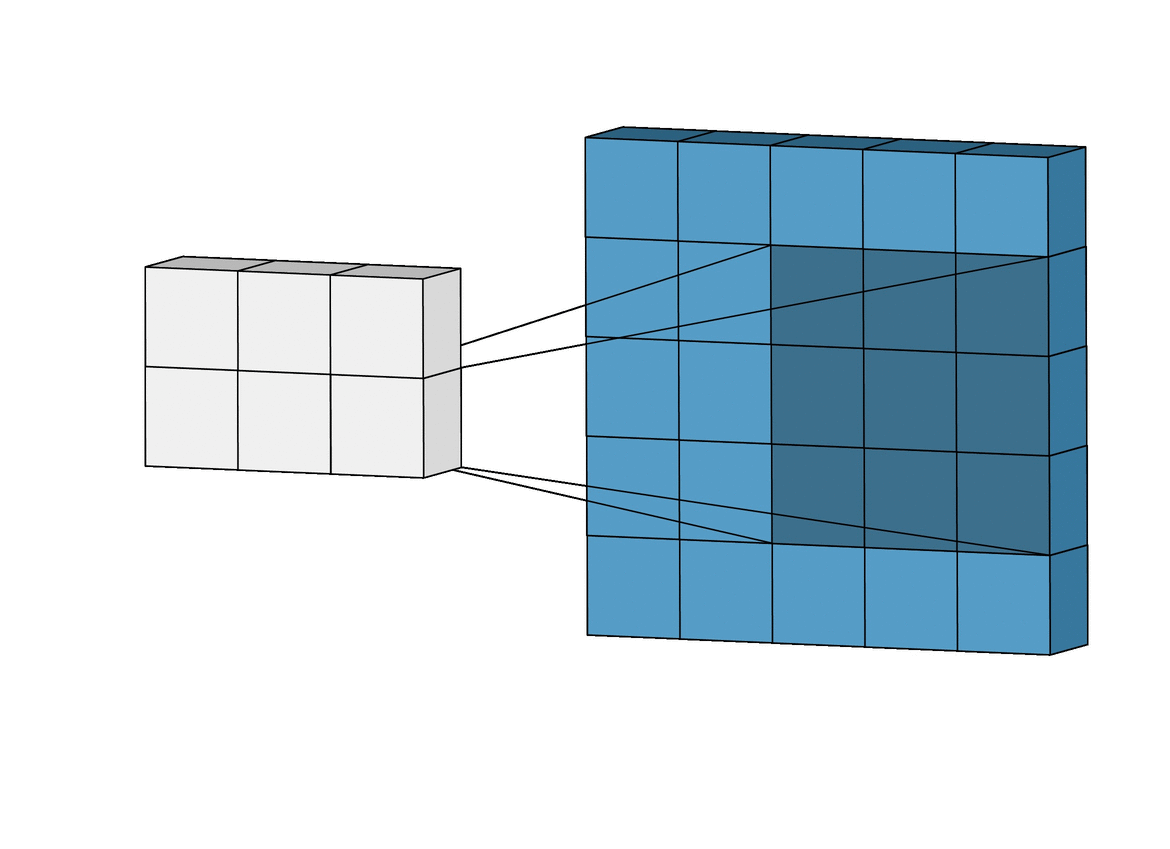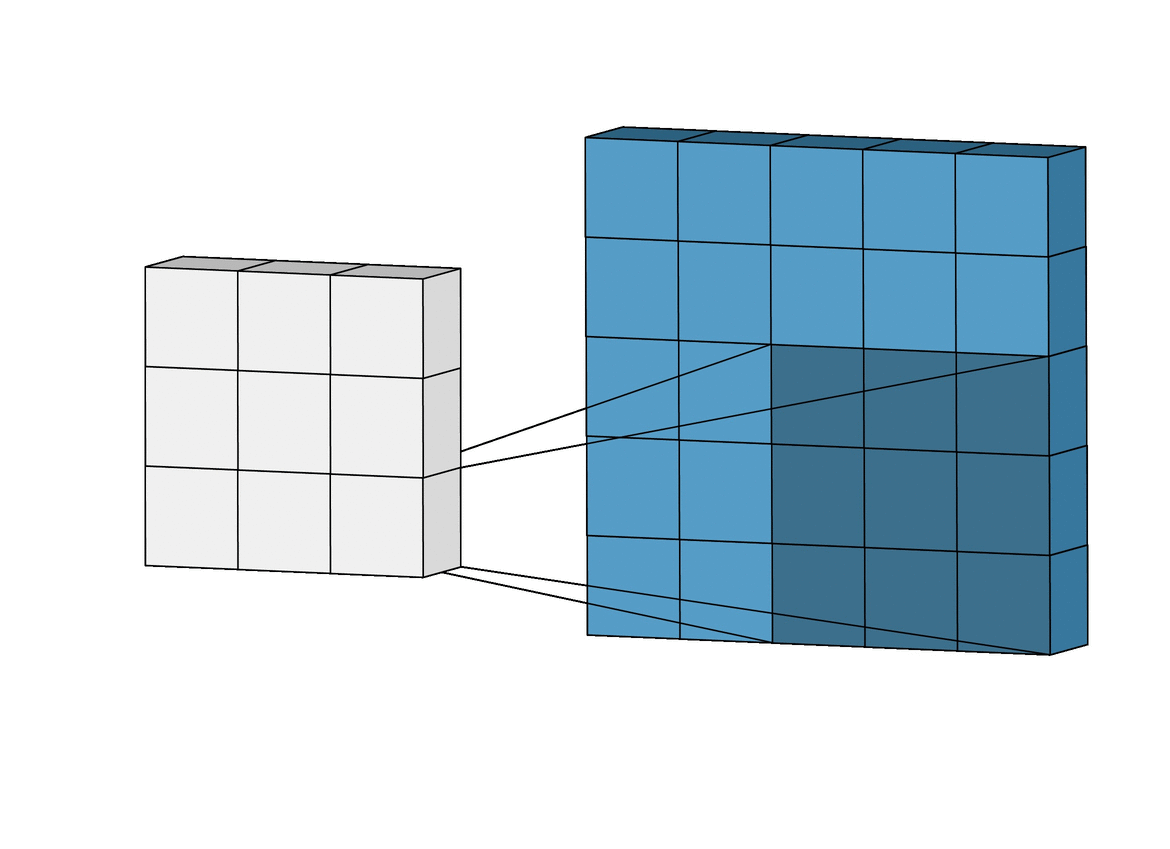 Convolution Operation
Convolution Operation
After the image has gone through a convolution, an operation called max pooling is often applied. Max pooling further reduces the dimensionality of the image by only taking the largest pixel values from each section of an image.
 Maximum Pooling
Maximum Pooling
These image features go through layers of convolution and maxpooling repeatedly until they are eventually flattened and fed into a traditional (fully connected) neural network. This network makes predictions using the extracted features.
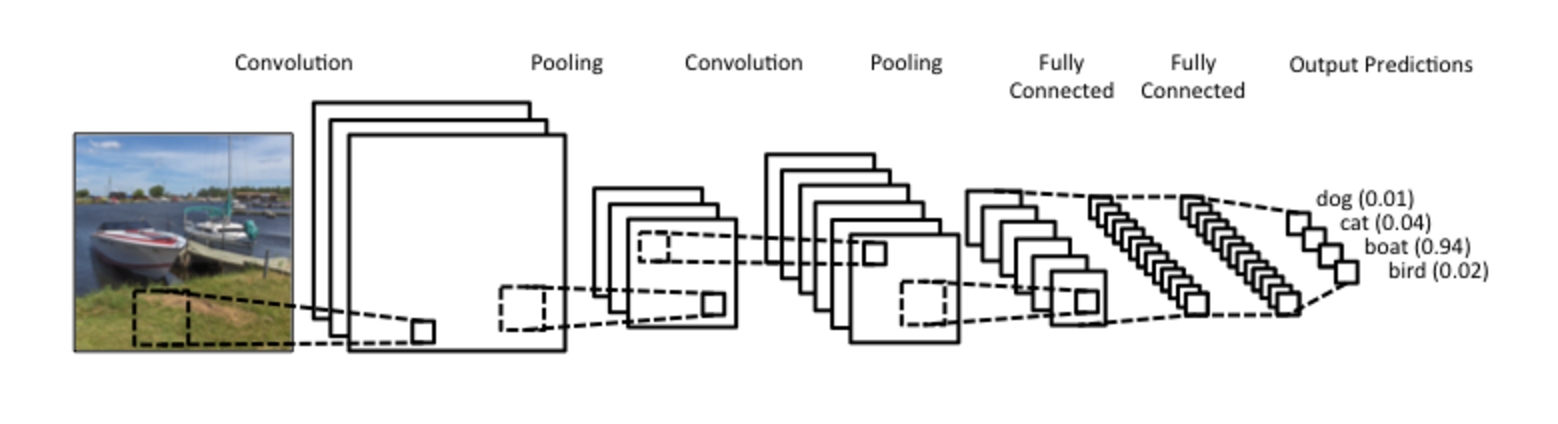 Sample Convolutional Network Architecture
Sample Convolutional Network Architecture
Classifying Insect Images with a Convolutional Neural Network
As an example, let’s use a convolutional neural network to classify images of insects. The goal is to determine whether a given image has a cockroach, dragonfly, or beetle.


 Cockroaches, Dragonflies, and Beetles
Cockroaches, Dragonflies, and Beetles
I’m going to start by using a pretrained network, called VGG-16, that has already been trained on the imagenet dataset. I kept all of the weights frozen except for the weights of the final layer. Additionally, I changed the output structure so it would only predict 3 classes: cockroach, dragonfly, or beetle. You can see the structure of the network below.
 Network Architecture of VGG-16
Network Architecture of VGG-16
We can visualize how the network extracts features from the image by looking at different layers of the network. Here you can see layers 5, 30, 100, and 300.


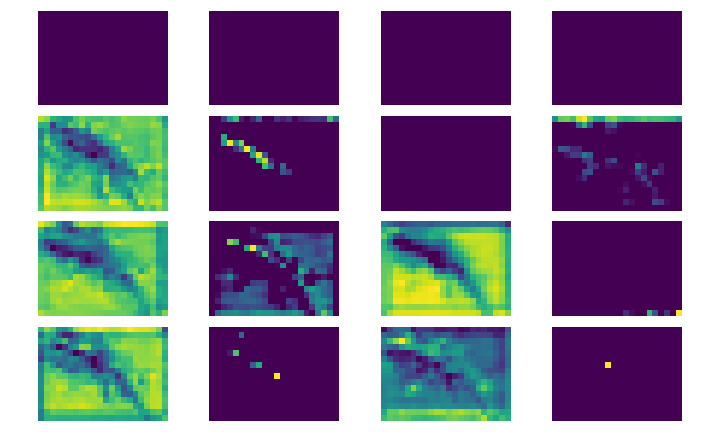
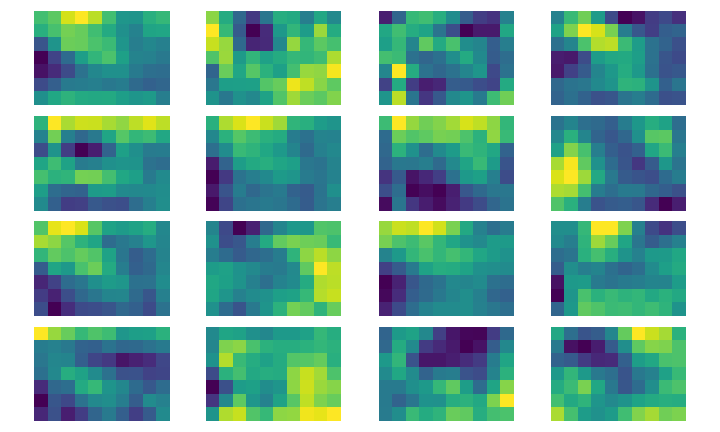 Layers 5, 30, 100, and 300
Layers 5, 30, 100, and 300
You can see that the features get broader and less detailed as you move into the deeper layers of the network. This shows that the model is creating a more compact representation of the image. In terms of training, I fed the images into the network in batches of 32 and trained for 4 total epochs. This resulted in an end accuracy of 99.4% on the validation data. Here’s a link to a notebook of my modeling process.
That’s all for my introduction to neural networks and deep learning! Feel free to check out my sources below if you want to learn more.
Sources
Overview of Neural Networks and Deep Learning