Creating a Database From Scratch
Data scientists, business analysts, and other data-focused professionals access SQL databases every day. However, we’re often so used to queries just working that we don’t stop to consider what goes into the creation of a database. Understanding how information is typically stored can allow you to more quickly understand a database’s structure and help you write more efficient queries. In this post, I’ll be taking song data collected using the spotifyr package and creating a SQLite database. This dataset contains information on a song such as its popularity, danceability, and appearances on playlists.
The first step in getting this data into a database is normalizing it. Normalization makes the database more efficient and flexible by reducing the amount of redundant data. The database is already in first normal form, as there are no columns that contain multiple data elements; the next step is to determine how to get it into third normal form. Third normal form is when every non-prime attribute is non-transitively dependent on every primary key. This sounds a bit jargony, I know, but an example may help clarify things.
A primary key is a value or set of values that uniquely identifies a set of attributes in a given table. In the current scenario, we have a unique track ID for every track in our dataset, so we could potentially use this as one of our primary keys. If the database was in third normal form all the other columns in the table would only be dependent on the track ID AND would not be transitively dependent on another column. Transitive dependence is when you know what the value of a column will be based on a column that is not the primary key of the table. This database is not currently in third normal form, as the present columns are dependent on non-primary-key values in the database.
For example, the track album name is transitively dependent on the track album ID; knowing the ID of the track means you KNOW the value of the track album ID which, in turn, means you KNOW the name of the album.
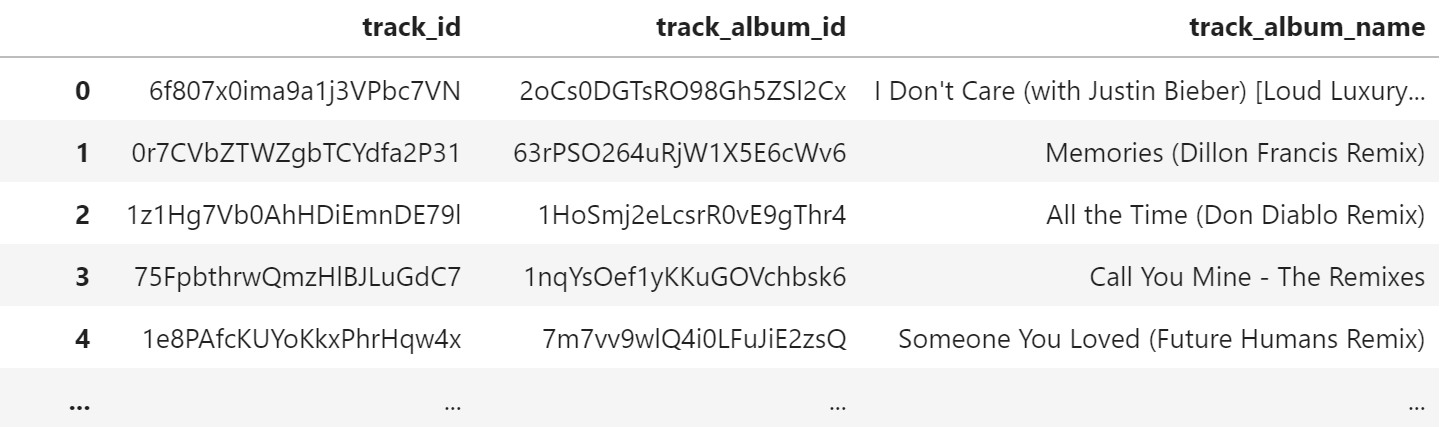 An Example of Transitive Dependence
An Example of Transitive Dependence
The goal is for the primary key to be the only information in a table that allows you to determine the other attributes of the record. We need to break the table up into smaller tables to fix this issue. I used the SQLite3 library to convert the data from a dataframe to individual tables in a database.
Here’s an overview of the end result:
| Table Name | Contents |
|---|---|
| tracks | track id and song characteristics |
| album_name | album name and album id |
| album release | album id and release date |
| playlist_genre | playlist id and genre |
| playlist_name | playlist name and playlist id |
| playlist_subgenre | playlist id and playlist genre |
| track_playlist | track id and playlist id |
| track_artist | track id and artist name |
Testing the Database
Now that we have our database we can start to explore song trends. One of the pieces of information Spotify records for each song is its “instrumentalness” - how likely a song is to be purely instrumental. Songs that have instrumentalness values of over .5 are typically seen as being instrumental. Let’s see which playlist has the highest number of instrumental songs. I limited the ouput to 10 rows to make it easier to see, as there were 256 playlists that had at least one instrumental song.
%%sql
SELECT PlaylistName, NumberInstrumentals
FROM (SELECT COUNT(DISTINCT(tracks.track_id)) as NumberInstrumentals, playlist_name.playlist_name as PlaylistName
FROM tracks
JOIN track_playlist ON track_playlist.track_id = tracks.track_id
JOIN track_name ON track_name.track_id = tracks.track_id
JOIN track_artist ON track_artist.track_id = tracks.track_id
JOIN playlist_name ON playlist_name.playlist_id = track_playlist.playlist_id
WHERE tracks.instrumentalness >.50
GROUP BY playlist_name.playlist_name
)
WHERE NumberInstrumentals > 0
ORDER BY NumberInstrumentals DESC
LIMIT 10
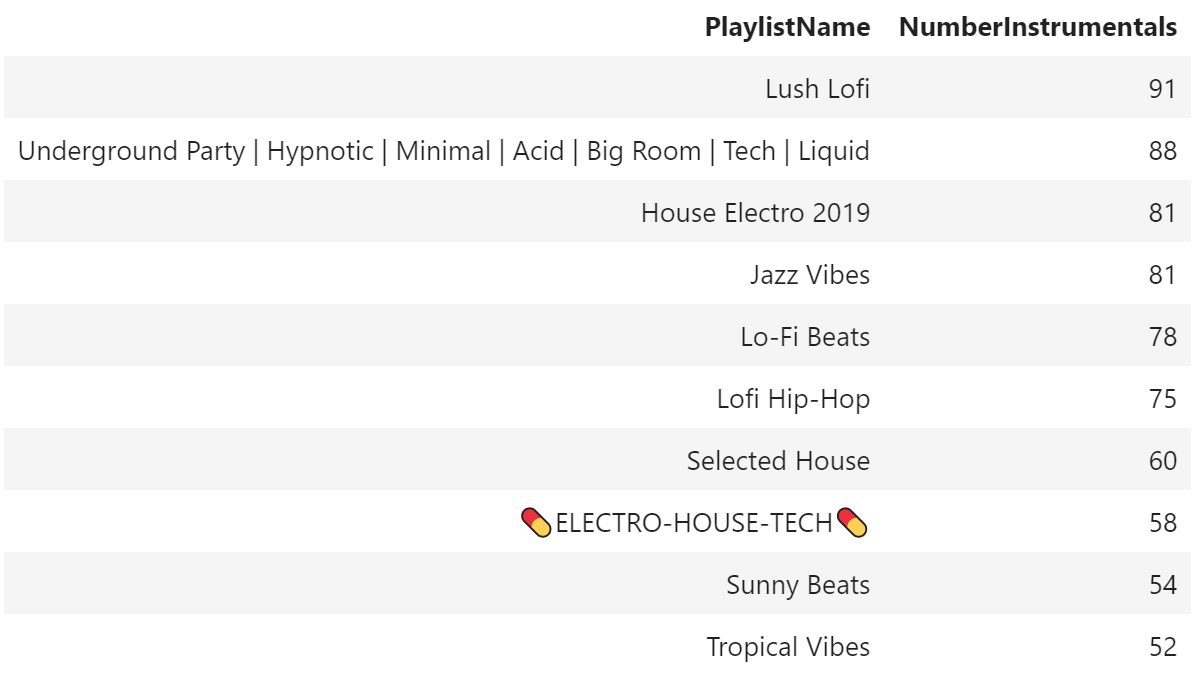 Playlists Containing the Most Instrumental Songs
Playlists Containing the Most Instrumental Songs
We can also take a look at which genres of music are the most danceable.
%%sql
SELECT AVG(tracks.danceability) as Danceability, playlist_genre.playlist_genre as Genre
FROM tracks
JOIN playlist_genre ON playlist_genre.playlist_id = track_playlist.playlist_id
JOIN track_playlist ON track_playlist.track_id = tracks.track_id
GROUP BY playlist_genre.playlist_genre
ORDER by AVG(tracks.danceability) DESC
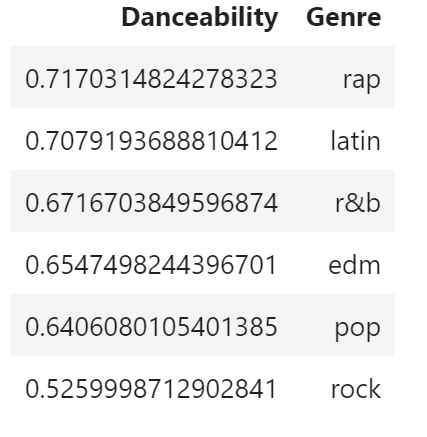
Genres by Danceability
Surprisingly (to me at least) it turns out that rap is the most danceable genre on average. I was thinking that pop or maybe EDM would come out on top. In the future I may look into the interaction between danceability and other factors such as tempo, energy, and loudness. It may be that there is another underlying relationship causing this result.